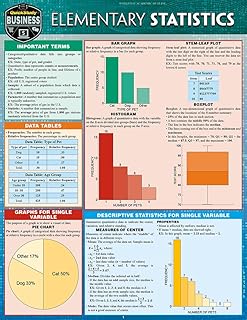
The relationship between sample variance and the variance law of large numbers is a fundamental concept in statistics, illustrating how the variability of a sample converges to the population variance as the sample size increases. Sample variance, calculated as the average of the squared differences from the sample mean, provides an estimate of the spread of data within a sample. According to the law of large numbers, as the sample size grows larger, the sample variance approaches the true population variance, assuming the data is drawn randomly and independently. This convergence is crucial because it ensures that large samples provide reliable estimates of population parameters, underpinning many statistical inferences and hypothesis tests. Thus, understanding this relationship not only clarifies the behavior of sample variance but also highlights the theoretical foundation for using large samples in empirical research.
| Characteristics | Values |
|---|---|
| Definition | The Law of Large Numbers (LLN) states that as the sample size increases, the sample variance converges to the population variance. |
| Mathematical Representation | Var(X̄) = σ²/n, where Var(X̄) is the sample variance, σ² is the population variance, and n is the sample size. |
| Convergence Type | The convergence is in probability, meaning the probability that the sample variance deviates from the population variance by more than a small amount approaches zero as the sample size increases. |
| Assumptions | 1. Independent and identically distributed (iid) random variables. 2. Finite population variance (σ² < ∞). |
| Implication | As n → ∞, Var(X̄) → 0, indicating that the sample mean becomes a more accurate estimate of the population mean. |
| Relationship to Central Limit Theorem (CLT) | The LLN is a fundamental concept that underpins the CLT, which describes the distribution of the sample mean as the sample size increases. |
| Practical Significance | The LLN justifies the use of large sample sizes in statistical inference, as it ensures that the sample variance provides a reliable estimate of the population variance. |
| Limitations | The LLN does not provide information about the rate of convergence or the distribution of the sample variance for finite sample sizes. |
| Example | Suppose a population has a variance of 25. As the sample size increases from 10 to 1000, the sample variance will approach 25, demonstrating the LLN in action. |
| Real-world Application | The LLN is applied in various fields, including quality control, finance, and survey research, where accurate estimation of population parameters is crucial. |
Explore related products






What You'll Learn
![]()
Understanding Sample Variance Calculation
Sample variance, a cornerstone of statistical analysis, quantifies the dispersion of data points within a sample relative to the sample mean. It is calculated as the average of the squared differences from the sample mean, often denoted as \( s^2 \). The formula \( s^2 = \frac{1}{n-1} \sum_{i=1}^{n} (x_i - \bar{x})^2 \) is familiar to practitioners, but its connection to the population variance (\( \sigma^2 \)) is less intuitive. This relationship is illuminated by the Law of Large Numbers, which asserts that as sample size increases, the sample variance converges to the population variance. For instance, in a clinical trial measuring blood pressure, a small sample might yield \( s^2 = 15 \), while the population variance \( \sigma^2 = 14.5 \). With a larger sample, say \( n = 1000 \), \( s^2 \) would approach 14.5, demonstrating this convergence.
To grasp why sample variance equals population variance under the Law of Large Numbers, consider the mechanics of the calculation. The squared differences from the mean penalize outliers more heavily, ensuring that extreme values do not distort the measure of spread. However, the use of \( n-1 \) in the denominator (Bessel's correction) is critical for unbiased estimation. Without it, the sample variance would systematically underestimate the population variance. For example, in a dataset of 20 exam scores, using \( n \) instead of \( n-1 \) might yield \( s^2 = 12 \), while the corrected version gives \( s^2 = 13.2 \), closer to the true population variance. This correction is particularly vital in small samples, where bias is more pronounced.
A practical example illustrates the interplay between sample size and variance estimation. Suppose a manufacturer tests the lifespan of 50 lightbulbs, finding \( s^2 = 200 \) hours. Doubling the sample size to 100 might yield \( s^2 = 195 \), and increasing it to 500 could result in \( s^2 = 192 \). This gradual reduction in variance reflects the Law of Large Numbers in action. For researchers, this underscores the importance of larger sample sizes, not just for precision in means but also for accurate variance estimation. In fields like quality control, where variance directly impacts defect rates, this convergence is not just theoretical but operationally critical.
Caution must be exercised when applying these principles, particularly in non-random or skewed datasets. The Law of Large Numbers assumes independent and identically distributed (i.i.d.) data, a condition often violated in real-world scenarios. For instance, a study on income distribution might exhibit high skewness, where a few extreme values inflate the variance. In such cases, robust estimators like the interquartile range or Winsorized variance may be preferable. Additionally, the rate of convergence depends on the distribution's kurtosis; heavier-tailed distributions (e.g., Cauchy) converge more slowly than lighter-tailed ones (e.g., normal). Practitioners should thus pair large samples with diagnostic checks for distributional assumptions.
In conclusion, understanding sample variance calculation requires recognizing its dual role as both a descriptive statistic and an estimator of population variance. The Law of Large Numbers provides the theoretical foundation for this duality, assuring that with sufficient data, sample variance becomes a reliable proxy for population variance. However, practical application demands awareness of biases, corrections, and distributional assumptions. By balancing theory with empirical rigor, analysts can leverage sample variance as a powerful tool for inference and decision-making across diverse fields.
Misrepresentation of Fact vs. Law: Key Differences Explained
You may want to see also
Explore related products





![The Law of Legitimation by Subsequent Marriage: Illustrative of the Variances Between the Laws ... 1829 [Leather Bound]](https://m.media-amazon.com/images/I/617DLHXyzlL._AC_UY218_.jpg)
![]()
Definition of Population Variance
Population variance is the average of the squared differences between each data point and the population mean. It quantifies the spread or dispersion of data in an entire population, serving as a foundational measure in statistics. Unlike sample variance, which estimates this spread from a subset of data, population variance considers every individual in the group, providing a definitive measure of variability. Mathematically, it is denoted as σ² and calculated by summing the squared differences from the mean, then dividing by the population size (N). This precise calculation distinguishes it from sample variance, which divides by (N-1) to correct for bias.
To illustrate, consider a population of 100 students’ test scores. If the mean score is 75, population variance would be computed by squaring the difference between each student’s score and 75, summing these values, and dividing by 100. This process yields a single, fixed value representing the inherent variability in the entire dataset. In contrast, if only 20 students’ scores were analyzed, the sample variance would provide an estimate of this variability, adjusted for the smaller dataset. Understanding this distinction is crucial for applying statistical principles accurately.
One practical application of population variance is in quality control. For instance, a manufacturer might measure the variance in the weight of 10,000 widgets produced in a day. A low variance indicates consistent production, while a high variance signals potential issues in the manufacturing process. Here, population variance is directly applicable because every widget is measured, not just a sample. This comprehensive analysis ensures that deviations are not overlooked, enabling precise adjustments to improve product uniformity.
However, calculating population variance is not always feasible. In large or infinite populations, measuring every individual is impractical or impossible. This limitation underscores the importance of the Law of Large Numbers, which states that as sample size increases, sample variance converges to population variance. For example, if a researcher studies the height of adult males in a country, measuring every individual is unfeasible. Instead, they rely on large samples, trusting that the sample variance will closely approximate the true population variance as the sample size grows.
In summary, population variance is a definitive measure of data spread, calculated using the entire dataset. Its practical applications range from quality control to scientific research, but its direct computation is often limited by logistical constraints. By understanding its definition and relationship to sample variance, statisticians can leverage the Law of Large Numbers to make accurate inferences about populations from sample data. This interplay between theory and application highlights the elegance and utility of statistical principles in real-world scenarios.
Jenny Sergeant and Colette Laws-Chapman's Six-Step Guide to Success
You may want to see also
Explore related products






![]()
Convergence of Sample Variance
The sample variance, a measure of spread in a dataset, is a cornerstone of statistical analysis. But how does this calculated value relate to the true, underlying variance of a population? This is where the Law of Large Numbers steps in, providing a crucial link between the two.
Imagine repeatedly drawing samples from a population and calculating the variance for each. The Law of Large Numbers assures us that as the sample size increases, these sample variances will converge towards the true population variance.
Understanding Convergence:
Think of it like aiming at a target. Each sample variance is like a shot fired. Initially, shots might scatter widely, but as you take more shots (increase sample size), they'll cluster tighter around the bullseye – the true population variance. This clustering represents convergence.
Mathematically, this convergence is expressed as:
Lim (n → ∞) s² = σ²
Where:
- s² is the sample variance
- σ² is the population variance
- n is the sample size
Why This Matters:
This convergence is fundamental for several reasons. Firstly, it justifies using sample variance as an estimate of population variance. Without this convergence, our estimates would be unreliable. Secondly, it underpins many statistical tests and confidence intervals, which rely on the assumption that sample statistics accurately reflect population parameters.
Practical Implications:
In real-world scenarios, we rarely have access to the entire population. We rely on samples. Understanding convergence allows us to make informed decisions about sample size. Larger samples generally lead to more accurate variance estimates, reducing the risk of drawing erroneous conclusions.
Cautions and Considerations:
While the Law of Large Numbers guarantees convergence in theory, practical considerations exist. The rate of convergence depends on the distribution of the population. Some distributions converge faster than others. Additionally, outliers can significantly impact sample variance, especially with smaller sample sizes.
When Juries Defy the Law: Consequences of Jury Nullification
You may want to see also
Explore related products






![]()
Role of Sample Size in LLN
The Law of Large Numbers (LLN) asserts that as sample size increases, the sample mean converges to the population mean. However, the role of sample size in this convergence is not limited to means; it also critically influences sample variance. Larger samples tend to produce more stable and accurate estimates of population variance, a phenomenon rooted in the relationship between sample size and the precision of statistical estimates. For instance, a sample size of 30 is often considered sufficient for the Central Limit Theorem to approximate the sampling distribution of the mean as normal, but variance estimation benefits from even larger samples due to its sensitivity to outliers and distribution shape.
To understand this, consider the formula for sample variance: \( s^2 = \frac{1}{n-1} \sum (x_i - \bar{x})^2 \). As \( n \) increases, the denominator grows, reducing the impact of individual deviations from the mean. This smoothing effect diminishes the influence of extreme values, making the sample variance a more reliable estimate of the population variance. For example, in a dataset with a true variance of 100, a sample of 100 observations might yield a variance estimate of 95, while a sample of 1,000 could yield 98—closer to the true value. This illustrates how larger samples reduce estimation error, aligning with the LLN's principle of convergence.
Practical applications highlight the importance of sample size in variance estimation. In clinical trials, for instance, small sample sizes (e.g., \( n < 50 \)) often result in wide confidence intervals for treatment effects due to high variance estimates. Increasing the sample size to 200 or more narrows these intervals, providing more precise estimates of both means and variances. Similarly, in quality control, larger sample sizes reduce the likelihood of Type II errors by ensuring that variance estimates are robust enough to detect meaningful deviations from standards.
However, increasing sample size is not without trade-offs. Larger samples require more resources—time, money, and effort—and diminishing returns may set in beyond a certain point. For example, increasing a sample from 1,000 to 10,000 might yield only marginal improvements in variance estimation while significantly increasing costs. Practitioners must balance these considerations, often using power calculations to determine the minimum sample size needed to achieve desired precision levels.
In conclusion, the role of sample size in the LLN extends beyond mean convergence to variance estimation. Larger samples enhance the reliability of variance estimates by reducing the impact of outliers and random fluctuations. While increasing sample size improves precision, practical constraints necessitate careful planning to optimize resource allocation. By understanding this dynamic, researchers and practitioners can leverage the LLN to produce more accurate and robust statistical inferences.
Is Lying on Job Applications Illegal? Legal Consequences Explained
You may want to see also
Explore related products






![]()
Bias Correction in Sample Variance
Sample variance, calculated as the average of squared deviations from the sample mean, systematically underestimates population variance. This bias arises because the sample mean, used as a proxy for the population mean, inherently reduces the observed spread of data. To illustrate, consider a dataset of 100 observations drawn from a normal distribution with a variance of 4. The sample variance, computed using the formula \( S^2 = \frac{1}{n-1} \sum (x_i - \bar{x})^2 \), will on average yield a value slightly below 4 due to the shrinkage effect of the sample mean.
Bias correction addresses this underestimation by adjusting the sample variance to better approximate the population variance. The most common correction involves multiplying the sample variance by \( \frac{n}{n-1} \), where \( n \) is the sample size. This adjustment, known as Bessel's correction, effectively counteracts the bias introduced by using the sample mean. For instance, if a sample of 20 observations yields a sample variance of 3.5, applying the correction would scale it to \( 3.5 \times \frac{20}{19} \approx 3.68 \), closer to the true population variance.
While Bessel's correction is widely applied, its effectiveness depends on sample size. For small samples (e.g., \( n < 30 \)), the correction significantly reduces bias, but for large samples (e.g., \( n > 100 \)), the difference between corrected and uncorrected variance becomes negligible. This aligns with the Law of Large Numbers, which states that as sample size increases, the sample variance converges to the population variance. However, in practical scenarios where sample sizes are moderate, applying the correction remains crucial for accurate estimation.
A cautionary note: over-reliance on bias correction can lead to misinterpretation if the underlying assumptions are violated. For example, if the data is not randomly sampled or contains outliers, the corrected variance may still be misleading. Practitioners should always assess data quality and distribution before applying corrections. Additionally, alternative estimators, such as the Maximum Likelihood Estimator (MLE), offer unbiased variance estimates under specific conditions but require stronger assumptions about data distribution.
In summary, bias correction in sample variance is a straightforward yet essential technique for improving estimation accuracy, particularly in small to moderate sample sizes. By understanding its mechanics, limitations, and relationship to the Law of Large Numbers, analysts can make informed decisions to ensure robust statistical inference. Always pair correction methods with diagnostic checks to validate their appropriateness for the data at hand.
Understanding the Sherman Act: Key Federal Antitrust Law Explained
You may want to see also
Frequently asked questions
The Law of Large Numbers states that as the sample size increases, the sample mean approaches the population mean. Similarly, the sample variance converges to the population variance, ensuring consistency in estimating variability as the sample size grows.
The Law of Large Numbers guarantees that the sample variance, calculated from a sufficiently large sample, will approximate the population variance. This is because the sample variance is an unbiased estimator, and its accuracy improves with larger sample sizes.
The Law of Large Numbers ensures convergence by reducing the difference between the sample variance and the population variance as the sample size increases. This is due to the averaging effect of larger samples, which minimizes the impact of random fluctuations.
No, the Law of Large Numbers applies as the sample size approaches infinity. For smaller samples, the sample variance may not exactly equal the population variance, but it becomes increasingly accurate as the sample size grows.