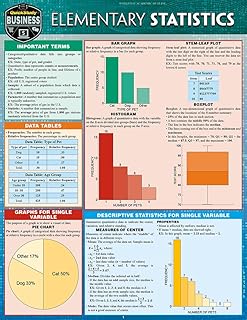
Setting up a power law model equation involves defining a relationship where one variable is proportional to a constant power of another variable, typically expressed as \( y = ax^b \), where \( y \) is the dependent variable, \( x \) is the independent variable, and \( a \) and \( b \) are constants. The parameter \( b \), known as the exponent, determines the shape of the curve, while \( a \) scales the relationship. To establish this model, one must first identify the variables of interest and collect relevant data. Next, apply logarithmic transformation to both sides of the equation, resulting in \( \log(y) = \log(a) + b \log(x) \), which linearizes the relationship and allows for linear regression to estimate \( a \) and \( b \). Finally, validate the model by assessing the goodness of fit and ensuring the assumptions of the power law hold for the given dataset. This approach is widely used in fields such as physics, biology, and economics to model phenomena that exhibit non-linear scaling behavior.
| Characteristics | Values |
|---|---|
| Definition | A mathematical relationship where one quantity varies as a power of another: ( y = ax^b ). |
| Key Parameters | ( a ) (scaling constant), ( b ) (power-law exponent). |
| Data Requirements | Paired data points ((x, y)) with ( x > 0 ). |
| Linearization Method | Transform to linear form: ( \log(y) = \log(a) + b \log(x) ). |
| Fitting Technique | Linear regression on ( \log(y) ) vs. ( \log(x) ). |
| Exponent Estimation | ( b ) is the slope of the linearized model. |
| Constant Estimation | ( a = 10^{\text} ) or ( e^{\text} ). |
| Assumptions | Relationship is strictly positive; power-law behavior holds across data range. |
| Goodness-of-Fit | Evaluate ( R^2 ) or residuals of the linearized model. |
| Applications | Scaling phenomena (e.g., fluid dynamics, network theory, economics). |
| Limitations | Sensitive to outliers; assumes data follows a true power law. |
| Software Tools | Python (NumPy, SciPy), R, MATLAB, Excel (with linear regression). |
| Example Equation | ( y = 2.5 \cdot x^{1.7} ) (if ( a = 2.5 ), ( b = 1.7 )). |
| Validation | Compare model predictions to empirical data; check residual plots. |
Explore related products






What You'll Learn
- Data Collection: Gather relevant data points for analysis, ensuring accuracy and completeness
- Plotting Data: Create a log-log plot to visualize the power law relationship
- Linear Regression: Apply linear regression to the log-transformed data for parameter estimation
- Parameter Interpretation: Understand the exponent and coefficient in the power law equation
- Model Validation: Test the model’s fit using residual analysis and predictive accuracy
![]()
Data Collection: Gather relevant data points for analysis, ensuring accuracy and completeness
To set up a power law model equation, the first and most critical step is Data Collection: Gather relevant data points for analysis, ensuring accuracy and completeness. This phase is foundational, as the quality of your data directly impacts the validity and reliability of the power law model. Begin by clearly defining the variables of interest—typically, one variable is plotted against another on a logarithmic scale to identify a linear relationship, which is characteristic of power laws. For example, if modeling the relationship between population size and city resources, ensure you collect data on both variables across a representative sample of cities. Use credible sources such as government databases, academic journals, or industry reports to ensure data accuracy.
When gathering data, prioritize completeness to avoid biases or gaps in your analysis. Incomplete datasets can lead to misleading conclusions, especially when dealing with power laws, which often describe scaling phenomena across multiple orders of magnitude. For instance, if analyzing the frequency distribution of word usage in a language, ensure your dataset includes words from various corpus sizes and genres. Missing rare or common words could skew the observed exponent in the power law equation. Additionally, document metadata such as time periods, geographic regions, or experimental conditions to account for potential confounding factors.
Accuracy is equally vital during data collection. Verify the consistency and precision of measurements by cross-referencing multiple sources or using standardized collection methods. For example, if collecting data on earthquake magnitudes to fit a Gutenberg-Richter law (a type of power law), ensure magnitudes are reported using the same scale (e.g., moment magnitude scale) across all records. Outliers or errors in the data should be identified and addressed—either by correcting them if they are measurement errors or by justifying their inclusion if they represent genuine extreme events. Tools like data validation scripts or statistical checks can aid in maintaining accuracy.
Another key aspect of data collection is relevance. Only gather data points that directly contribute to the relationship you aim to model. Irrelevant data can introduce noise and complicate the identification of the power law exponent. For instance, when modeling the relationship between company revenue and employee count, exclude data from non-profit organizations or government agencies, as their operational structures differ significantly from for-profit companies. Focus on datasets that span a wide range of values for both variables to ensure the power law behavior is observable across scales.
Finally, transparency in data collection methods is essential for reproducibility and credibility. Document every step of the process, including data sources, collection dates, and any preprocessing steps like filtering or normalization. This documentation allows others to replicate your analysis and verify your findings. For example, if using web-scraped data to analyze the distribution of user engagement on social media platforms, provide details on the scraping algorithm, date ranges, and platforms included. By ensuring accuracy, completeness, relevance, and transparency in data collection, you lay a robust foundation for setting up and validating a power law model equation.
Adopting English Legal Traditions: The Foundations of Our Legal System
You may want to see also
Explore related products

$7.99 $24.99

$62.99 $62.99

$116.77 $179.99



![]()
Plotting Data: Create a log-log plot to visualize the power law relationship
When plotting data to visualize a power law relationship, creating a log-log plot is a fundamental step. A power law relationship is typically expressed as \( y = ax^b \), where \( a \) is a constant and \( b \) is the exponent. In a log-log plot, both the x-axis and y-axis are transformed using logarithms, which linearizes the power law relationship, making it easier to identify and analyze. This transformation converts the equation to \( \log(y) = \log(a) + b \log(x) \), effectively turning the curved relationship into a straight line with a slope of \( b \) and a y-intercept of \( \log(a) \).
To create a log-log plot, start by preparing your data. Ensure both your independent variable \( x \) and dependent variable \( y \) are positive, as logarithms are undefined for non-positive values. Next, compute the logarithms of both \( x \) and \( y \) using a base of your choice, typically base 10 or natural logarithm (base \( e \)). Most data analysis tools, such as Python (with libraries like NumPy and Matplotlib), Excel, or MATLAB, have built-in functions to compute logarithms. Once the logarithmic transformations are applied, you can plot \( \log(y) \) against \( \log(x) \).
When plotting, label the axes clearly as "log(x)" and "log(y)" to indicate the logarithmic transformation. If the data follows a power law, the resulting plot should appear as a straight line. The slope of this line corresponds to the exponent \( b \) in the power law equation, and the y-intercept can be used to determine \( a \). To find the slope, you can use linear regression on the log-log data points, which will provide an estimate of \( b \). The intercept of the regression line, when converted back from logarithmic space, gives \( a \).
It’s important to inspect the log-log plot for deviations from linearity, as these may indicate that the power law model is not appropriate for the entire range of data. Additionally, consider adding a trendline to the plot to visually represent the linear fit and make it easier to interpret the slope and intercept. Ensure the trendline equation is displayed on the plot for clarity. This visual representation not only aids in understanding the relationship but also serves as a diagnostic tool for model validation.
Finally, after creating the log-log plot and confirming the linearity, you can use the slope and intercept to write the power law equation. Convert the intercept back to its original scale by exponentiating it (e.g., \( a = 10^{\text{intercept}} \) if using base 10 logarithms). This equation can then be used to predict \( y \) for given values of \( x \) or to further analyze the relationship. By following these steps, you effectively leverage the log-log plot to visualize and quantify the power law relationship in your data.
Obama's Hope Poster: The Copyright Battle and Legal Aftermath
You may want to see also
Explore related products

$99 $109.99





![]()
Linear Regression: Apply linear regression to the log-transformed data for parameter estimation
When setting up a power law model equation, one effective approach is to apply linear regression to the log-transformed data for parameter estimation. This method is particularly useful because power law relationships often exhibit linear behavior when transformed logarithmically. The general form of a power law model is \( y = ax^b \), where \( a \) is the scaling parameter and \( b \) is the exponent. To estimate these parameters using linear regression, the first step is to take the natural logarithm of both sides of the equation, resulting in \( \ln(y) = \ln(a) + b\ln(x) \). This transformation converts the power law relationship into a linear equation, where \( \ln(a) \) is the intercept and \( b \) is the slope.
Once the data is log-transformed, the next step is to apply linear regression to estimate the parameters \( \ln(a) \) and \( b \). This involves fitting a straight line to the scatter plot of \( \ln(y) \) versus \( \ln(x) \). Most statistical software packages, such as Python’s `scipy` or `statsmodels`, or R’s `lm` function, can perform this regression. The output of the regression will provide the estimated values of the intercept (corresponding to \( \ln(a) \)) and the slope (corresponding to \( b \)). It is crucial to ensure that the data points are appropriately transformed before fitting the model, as errors in transformation can lead to inaccurate parameter estimates.
After obtaining the estimates for \( \ln(a) \) and \( b \), the final step is to convert these back to the original scale to derive the power law equation. The scaling parameter \( a \) is calculated as \( a = e^{\ln(a)} \), which simplifies to \( a \) itself. The exponent \( b \) remains unchanged, as it is directly estimated from the regression. Thus, the power law model equation is \( y = ax^b \), with \( a \) and \( b \) now known. This equation can then be used to describe the relationship between the variables \( y \) and \( x \) in the original data.
It is important to validate the model by checking the goodness of fit, typically through metrics like \( R^2 \) or residual analysis. A high \( R^2 \) value indicates that the linear regression on the log-transformed data explains a significant portion of the variability in the data. Additionally, plotting the residuals can help identify any systematic patterns that may suggest deviations from the power law assumption. If the residuals are randomly scattered around zero, it supports the validity of the power law model.
In summary, applying linear regression to log-transformed data is a straightforward and effective method for estimating the parameters of a power law model. By transforming the data, fitting a linear regression, and converting the estimates back to the original scale, one can derive a power law equation that accurately describes the relationship between the variables. This approach is widely used in various fields, including physics, biology, and economics, where power law relationships are commonly observed.
Understanding the Cash and Carry Law: A Historical Overview
You may want to see also
Explore related products






![]()
Parameter Interpretation: Understand the exponent and coefficient in the power law equation
The power law model is a fundamental concept in various scientific and mathematical fields, often used to describe relationships where one quantity varies as a power of another. The general form of the power law equation is \( y = ax^b \), where \( y \) is the dependent variable, \( x \) is the independent variable, \( a \) is the coefficient (or prefactor), and \( b \) is the exponent. Understanding the roles of the coefficient and exponent is crucial for interpreting the behavior of the model and its applicability to real-world scenarios.
Coefficient (a): The coefficient \( a \) in the power law equation represents the proportionality constant or scaling factor. It determines the vertical scaling of the relationship between \( y \) and \( x \). If \( a \) is large, the values of \( y \) will be proportionally larger for the same values of \( x \), and vice versa. For example, in a model describing the relationship between a company's revenue (\( y \)) and its number of customers (\( x \)), a larger \( a \) might indicate higher revenue per customer. The coefficient also provides insights into the initial conditions or baseline of the system being modeled. In many cases, \( a \) is determined empirically through data fitting or derived from theoretical considerations specific to the problem domain.
Exponent (b): The exponent \( b \) in the power law equation governs the shape of the relationship between \( y \) and \( x \). It defines how \( y \) changes as \( x \) changes, specifically whether the relationship is linear, sublinear, or superlinear. If \( b = 1 \), the relationship is linear, meaning \( y \) increases at the same rate as \( x \). If \( 0 < b < 1 \), the relationship is sublinear, indicating that \( y \) increases more slowly than \( x \). Conversely, if \( b > 1 \), the relationship is superlinear, meaning \( y \) increases more rapidly than \( x \). For instance, in a model describing the spread of a disease (\( y \)) based on the number of infected individuals (\( x \)), an exponent greater than 1 would suggest exponential growth. The value of \( b \) is often critical in understanding the underlying mechanisms driving the relationship and can be estimated using regression techniques or theoretical models.
Interaction Between Coefficient and Exponent: While \( a \) and \( b \) play distinct roles, their interaction is essential for a comprehensive interpretation of the power law model. The coefficient \( a \) sets the overall scale, while the exponent \( b \) determines the rate of change. Together, they define the unique characteristics of the relationship. For example, in a model describing the strength of materials (\( y \)) based on their thickness (\( x \)), a small \( a \) combined with a large \( b \) might indicate that even a slight increase in thickness leads to a significant improvement in strength. Understanding this interplay is key to applying the model effectively and making accurate predictions.
Practical Considerations: When interpreting the parameters of a power law model, it is important to consider the context of the problem. The values of \( a \) and \( b \) should align with theoretical expectations or empirical observations. For instance, in natural phenomena like the distribution of city sizes or the frequency of words in a language, specific ranges of \( b \) are often observed. Additionally, the units of \( x \) and \( y \) influence the interpretation of \( a \), as it must ensure dimensional consistency in the equation. Careful attention to these details ensures that the model is both mathematically sound and practically meaningful.
In summary, the coefficient \( a \) and exponent \( b \) in the power law equation \( y = ax^b \) serve distinct but interconnected roles. The coefficient determines the vertical scaling and baseline of the relationship, while the exponent defines its shape and rate of change. Proper interpretation of these parameters requires a clear understanding of their individual contributions and their interaction, as well as careful consideration of the problem context. Mastery of these concepts enables effective application of the power law model across diverse fields.
The Disappearance of North Woods Law: Maine's Untold Story
You may want to see also
Explore related products


$20.99 $29.99




![]()
Model Validation: Test the model’s fit using residual analysis and predictive accuracy
Model validation is a critical step in ensuring that a power law model accurately represents the underlying data and can be reliably used for predictions. One of the primary methods to assess the model's fit is through residual analysis. Residuals are the differences between the observed values and the values predicted by the model. For a power law model, which typically takes the form \( y = ax^b \), residuals should be randomly distributed around zero without any discernible pattern. To perform residual analysis, first calculate the residuals for each data point. Plot these residuals against the independent variable \( x \) or the predicted values \( \hat{y} \). If the model fits well, the residual plot should show no systematic trends, such as increasing or decreasing patterns, and the points should fall within a horizontal band around zero. Additionally, a normal probability plot of the residuals can be used to check for normality, which is often assumed in regression models.
Another aspect of residual analysis is examining the magnitude of the residuals. Large residuals may indicate outliers or areas where the model performs poorly. It is important to investigate these points to determine whether they are due to measurement errors, unusual data points, or limitations of the power law model itself. Statistical measures such as the root mean squared error (RMSE) and mean absolute error (MAE) can quantify the average magnitude of the residuals, providing a numerical summary of the model's fit. Lower values of RMSE and MAE indicate a better fit. However, these metrics should be interpreted in the context of the data scale, as they are not standardized.
Predictive accuracy is another key component of model validation. To assess how well the power law model generalizes to new data, it is essential to evaluate its performance on a separate dataset not used in the model fitting process. This can be done through techniques such as cross-validation or by splitting the data into training and testing sets. For the testing set, compute the predicted values using the fitted power law equation and compare them to the actual observed values. Metrics such as \( R^2 \) (coefficient of determination) can be used to quantify the proportion of variance in the dependent variable explained by the model. However, \( R^2 \) alone is not sufficient; it should be complemented with other metrics like RMSE and MAE to provide a comprehensive assessment of predictive accuracy.
In addition to quantitative metrics, visual inspection of the model's predictions can provide valuable insights. Plotting the observed values against the predicted values for the testing dataset should yield a scatter plot with points closely following the 45-degree line, indicating high agreement between the model and the data. Deviations from this line suggest areas where the model may be underperforming. For power law models, it is also useful to plot the data on a log-log scale, as the relationship should appear linear if the power law assumption holds. Any curvature or deviation from linearity on this plot may indicate that the power law model is not appropriate.
Finally, it is important to consider the domain of applicability of the power law model when evaluating its fit and predictive accuracy. Power laws often describe phenomena over specific ranges of the independent variable, and extrapolation beyond these ranges can lead to unreliable predictions. During validation, ensure that the model is tested within the same range of \( x \) values as the training data. If the model is intended for extrapolation, additional scrutiny and justification are required, as power laws may not hold outside the observed data range. By combining residual analysis and predictive accuracy assessments, researchers can confidently determine whether a power law model is valid and suitable for its intended purpose.
Oklahoma Pocket Knife Laws: What You Need to Know
You may want to see also
Frequently asked questions
A power law model equation is a mathematical relationship of the form \( y = a \cdot x^b \), where \( a \) and \( b \) are constants. It is used to model phenomena where one quantity varies as a power of another, such as in physics, economics, or biology, when the relationship is non-linear and scales exponentially.
The constants \( a \) and \( b \) can be determined using regression analysis, such as linear regression on the logarithmic transformation of the data. Take the natural logarithm of both sides of the equation to get \( \ln(y) = \ln(a) + b \cdot \ln(x) \), then fit a straight line to the log-transformed data to estimate \( \ln(a) \) and \( b \).
1. Collect paired data points \((x, y)\). 2. Take the natural logarithm of both \( x \) and \( y \) to transform the data. 3. Perform linear regression on \( \ln(y) \) vs. \( \ln(x) \) to estimate the slope \( b \) and intercept \( \ln(a) \). 4. Convert the intercept back to \( a \) using \( a = e^{\ln(a)} \). 5. Write the power law equation as \( y = a \cdot x^b \).
Validate the model by checking the coefficient of determination (\( R^2 \)) from the regression analysis, which indicates how well the model fits the data. Additionally, plot the original data on a log-log scale and verify that the points align closely with a straight line. Residual analysis can also be used to assess the model's accuracy.